2024年7月5日,理想汽車在2024智能駕駛夏季發布會宣布將于7月內向全量理想AD Max用戶推送“全國都能開”的無圖NOA,并將于7月內推送全自動AES(自動緊急轉向)和全方位低速AEB(自動緊急制動)。同時,理想汽車發布了基于端到端模型、VLM視覺語言模型和世界模型的全新自動駕駛技術架構,并開啟新架構的早鳥計劃。
智能駕駛產品方面,無圖NOA不再依賴高精地圖或先驗信息,在全國范圍內的導航覆蓋區域均可使用,并借助時空聯合規劃能力帶來更絲滑的繞行體驗。無圖NOA也具備超遠視距導航選路能力,在復雜路口依然可以順暢通行。同時,無圖NOA充分考慮用戶心理安全邊界,用分米級微操帶來默契安心的智駕體驗。此外,即將推送的AES功能可以實現不依賴人輔助扭力的全自動觸發,規避更多高危事故風險。全方位低速AEB則再次拓展主動安全風險場景,有效減少低速挪車場景的高頻剮蹭事故發生。
自動駕駛技術方面,新架構由端到端模型、VLM視覺語言模型和世界模型共同構成。端到端模型用于處理常規的駕駛行為,從傳感器輸入到行駛軌跡輸出只經過一個模型,信息傳遞、推理計算和模型迭代更高效,駕駛行為更擬人。VLM視覺語言模型具備強大的邏輯思考能力,可以理解復雜路況、導航地圖和交通規則,應對高難度的未知場景。同時,自動駕駛系統將在基于世界模型構建的虛擬環境中進行能力學習和測試。世界模型結合重建和生成兩種路徑,構建的測試場景既符合真實規律,也兼具優秀的泛化能力。
理想汽車產品部高級副總裁范皓宇表示:“理想汽車始終堅持和用戶共同打磨產品體驗,從今年5月推送首批千名體驗用戶,到6月將體驗用戶規模擴展至萬人以上,我們已經在全國各地積累了超百萬公里的無圖NOA行駛里程。無圖NOA全量推送后,24萬名理想AD Max車主都將用上這款先進的智能駕駛產品,這是一項誠意滿滿的重磅升級。”
理想汽車智能駕駛研發副總裁郎咸朋表示:“從2021年啟動全棧自研,到今天發布全新的自動駕駛技術架構,理想汽車的自動駕駛研發從未停止探索的腳步。我們結合端到端模型和VLM視覺語言模型,帶來了業界率先在車端部署雙系統的方案,也率先將VLM視覺語言模型成功部署在車端芯片上,這套業內先進的全新架構是自動駕駛領域里程碑式的技術突破。”
無圖NOA四項能力提升,全國道路高效通行

將于7月內推送的無圖NOA帶來四項重大能力升級,全面提升用戶體驗。首先,得益于感知、理解和道路結構構建能力的全面提升,無圖NOA擺脫了對先驗信息的依賴。用戶在全國范圍內有導航覆蓋的城市范圍內均可使用NOA,甚至可以在更特殊的胡同窄路和鄉村小路開啟功能。
其次,基于高效的時空聯合規劃能力,車輛對道路障礙物的避讓和繞行更加絲滑。時空聯合規劃實現了橫縱向空間的同步規劃,并通過持續預測自車與他車的空間交互關系,規劃未來時間窗口內的所有可行駛軌跡。基于優質樣本的學習,車輛可以快速篩選最優軌跡,果斷而安全地執行繞行動作。
在復雜的城市路口,無圖NOA的選路能力也得到顯著提升。無圖NOA采用BEV視覺模型融合導航匹配算法,實時感知變化的路沿、路面箭頭標識和路口特征,并將車道結構和導航特征充分融合,有效解決了復雜路口難以結構化的問題,具備超遠視距導航選路能力,路口通行更穩定。
同時,無圖NOA重點考慮用戶心理安全邊界,用分米級的微操能力帶來更加默契、安心的行車體驗。通過激光雷達與視覺前融合的占用網絡,車輛可以識別更大范圍內的不規則障礙物,感知精度也更高,從而對其他交通參與者的行為實現更早、更準確的預判。得益于此,車輛能夠與其他交通參與者保持合理距離,加減速時機也更加得當,有效提升用戶行車時的安全感。
主動安全能力進階,覆蓋場景再拓展

在主動安全領域,理想汽車建立了完備的安全風險場景庫,并根據出現頻次和危險程度分類,持續提升風險場景覆蓋度,即將在7月內為用戶推送全自動AES和全方位低速AEB功能。
為了應對AEB也無法規避事故的物理極限場景,理想汽車推出了全自動觸發的AES自動緊急轉向功能。在車輛行駛速度較快時,留給主動安全系統的反應時間極短,部分情況下即使觸發AEB,車輛全力制動仍無法及時剎停。此時,AES功能將被及時觸發,無需人為參與轉向操作,自動緊急轉向,避讓前方目標,有效避免極端場景下的事故發生。
全方位低速AEB則針對泊車和低速行車場景,提供了360度的主動安全防護。在復雜的地庫停車環境中,車輛周圍的立柱、行人和其他車輛等障礙物都增加了剮蹭風險。全方位低速AEB能夠有效識別前向、后向和側向的碰撞風險,及時緊急制動,為用戶的日常用車帶來更安心的體驗。
自動駕駛技術突破創新,雙系統更智能

理想汽車的自動駕駛全新技術架構受諾貝爾獎得主丹尼爾·卡尼曼的快慢系統理論啟發,在自動駕駛領域模擬人類的思考和決策過程,形成更智能、更擬人的駕駛解決方案。
快系統,即系統1,善于處理簡單任務,是人類基于經驗和習慣形成的直覺,足以應對駕駛車輛時95%的常規場景。慢系統,即系統2,是人類通過更深入的理解與學習,形成的邏輯推理、復雜分析和計算能力,在駕駛車輛時用于解決復雜甚至未知的交通場景,占日常駕駛的約5%。系統1和系統2相互配合,分別確保大部分場景下的高效率和少數場景下的高上限,成為人類認知、理解世界并做出決策的基礎。
理想汽車基于快慢系統理論形成了自動駕駛算法架構的原型。系統1由端到端模型實現,具備高效、快速響應的能力。端到端模型接收傳感器輸入,并直接輸出行駛軌跡用于控制車輛。系統2由VLM視覺語言模型實現,其接收傳感器輸入后,經過邏輯思考,輸出決策信息給到系統1。雙系統構成的自動駕駛能力還將在云端利用世界模型進行訓練和驗證。
高效率的端到端模型
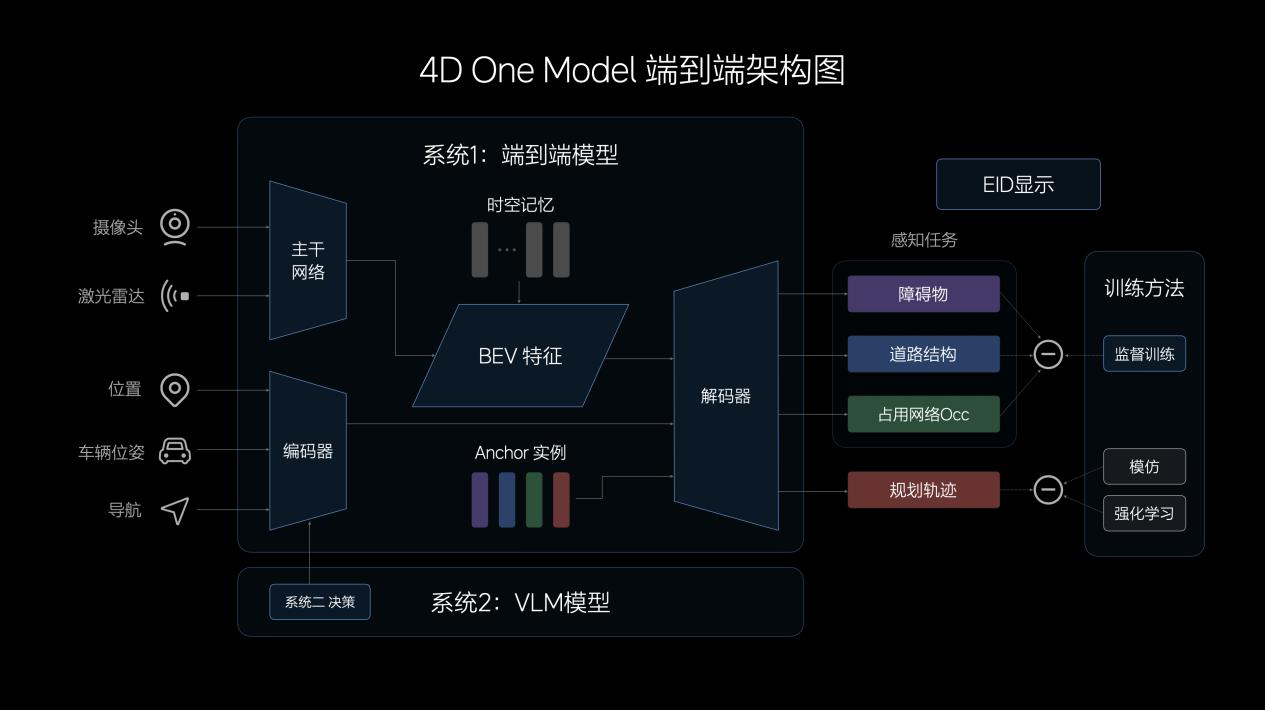
端到端模型的輸入主要由攝像頭和激光雷達構成,多傳感器特征經過CNN主干網絡的提取、融合,投影至BEV空間。為提升模型的表征能力,理想汽車還設計了記憶模塊,兼具時間和空間維度的記憶能力。在模型的輸入中,理想汽車還加入了車輛狀態信息和導航信息,經過Transformer模型的編碼,與BEV特征共同解碼出動態障礙物、道路結構和通用障礙物,并規劃出行車軌跡。
多任務輸出在一體化的模型中得以實現,中間沒有規則介入,因此端到端模型在信息傳遞、推理計算、模型迭代上均具有顯著優勢。在實際駕駛中,端到端模型展現出更強大的通用障礙物理解能力、超視距導航能力、道路結構理解能力,以及更擬人的路徑規劃能力。
高上限的VLM視覺語言模型
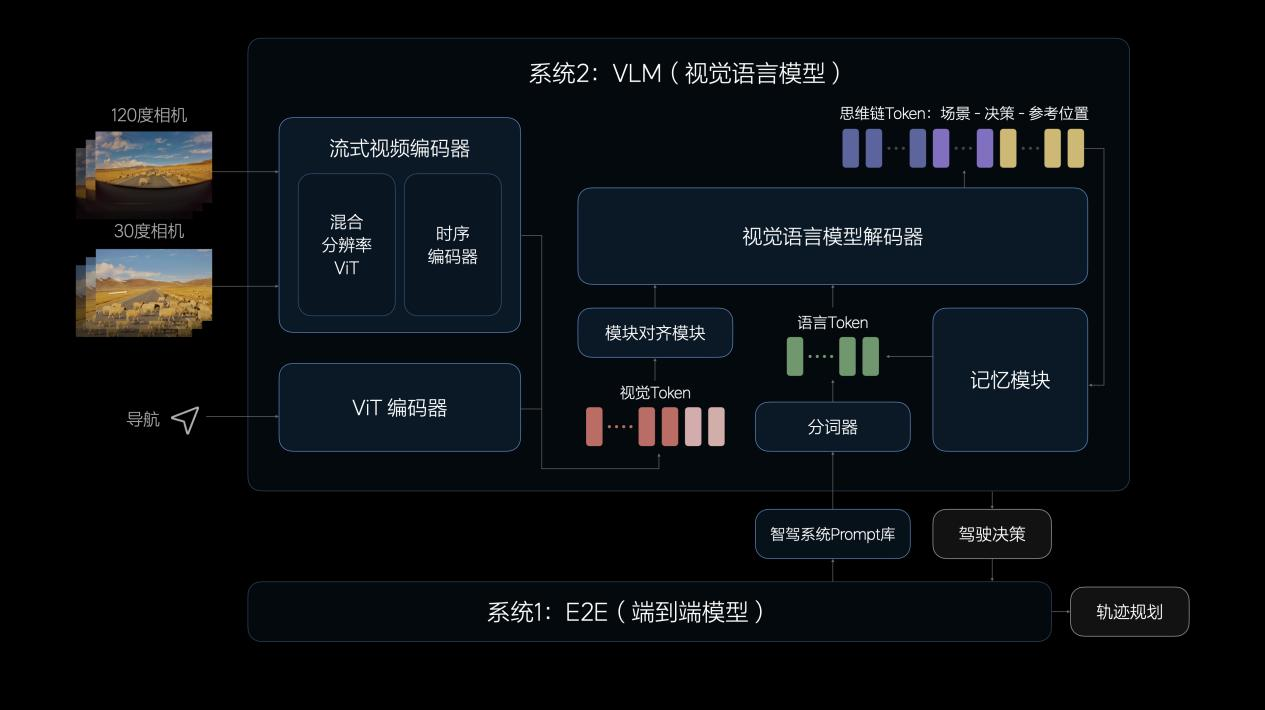
VLM視覺語言模型的算法架構由一個統一的Transformer模型組成,將Prompt(提示詞)文本進行Tokenizer(分詞器)編碼,并將前視相機的圖像和導航地圖信息進行視覺信息編碼,再通過圖文對齊模塊進行模態對齊,最終統一進行自回歸推理,輸出對環境的理解、駕駛決策和駕駛軌跡,傳遞給系統1輔助控制車輛。
理想汽車的VLM視覺語言模型參數量達到22億,對物理世界的復雜交通環境具有強大的理解能力,即使面對首次經歷的未知場景也能自如應對。VLM模型可以識別路面平整度、光線等環境信息,提示系統1控制車速,確保駕駛安全舒適。VLM模型也具備更強的導航地圖理解能力,可以配合車機系統修正導航,預防駕駛時走錯路線。同時,VLM模型可以理解公交車道、潮汐車道和分時段限行等復雜的交通規則,在駕駛中作出合理決策。
重建生成結合的世界模型
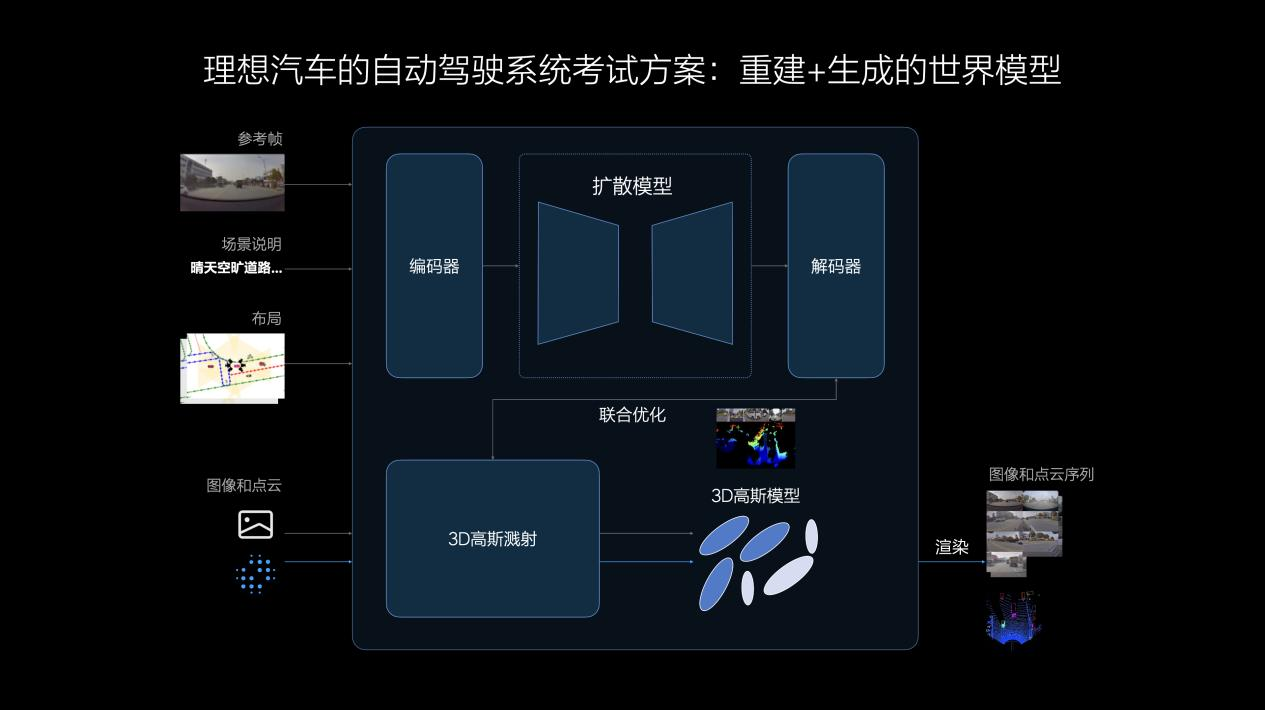
理想汽車的世界模型結合了重建和生成兩種技術路徑,將真實數據通過3DGS(3D高斯濺射)技術進行重建,并使用生成模型補充新視角。在場景重建時,其中的動靜態要素將被分離,靜態環境得到重建,動態物體則進行重建和新視角生成。再經過對場景的重新渲染,形成3D的物理世界,其中的動態資產可以被任意編輯和調整,實現場景的部分泛化。相比重建,生成模型具有更強的泛化能力,天氣、光照、車流等條件均可被自定義改變,生成符合真實規律的新場景,用于評價自動駕駛系統在各種條件下的適應能力。
重建和生成兩者結合所構建的場景為自動駕駛系統能力的學習和測試創造了更優秀的虛擬環境,使系統具備了高效閉環的迭代能力,確保系統的安全可靠。